|
Haoying Sun | 孙昊英 😄 😄 😄 我正在寻找2027年的工作机会,我的兴趣方向包括视频分析、图像修复、多模态预训练、多模态大语言模型、计算机视觉或其他与多模态相关的领域!!!欢迎通过微信与我联系(微信号:Alocus) 😄 😄 😄 I am currently seeking job opportunities for 2027. My research interests include video analysis, image restoration, multimodal pre-training, multimodal large language models, computer vision, or other multimodal-related fields!!! Feel free to contact me via WeChat (ID: Alocus) I am a Ph.D. student at Beijing University of Technology. My research focuses on sports video understanding, multimodal learning, video captioning, low-level vision, diffusion models, and knowledge graphs. I received my M.S. degree from Minzu University of China. |

|
ResearchI'm interested in computer vision, deep learning, and image processing. Most of my research focuses on video understanding, especially video captioning and identity-aware sports video captioning. Previously, I worked on image restoration tasks, including image dehazing and digital restoration of Dunhuang murals. My master's thesis was centered on the digital restoration of Dunhuang murals. |
|
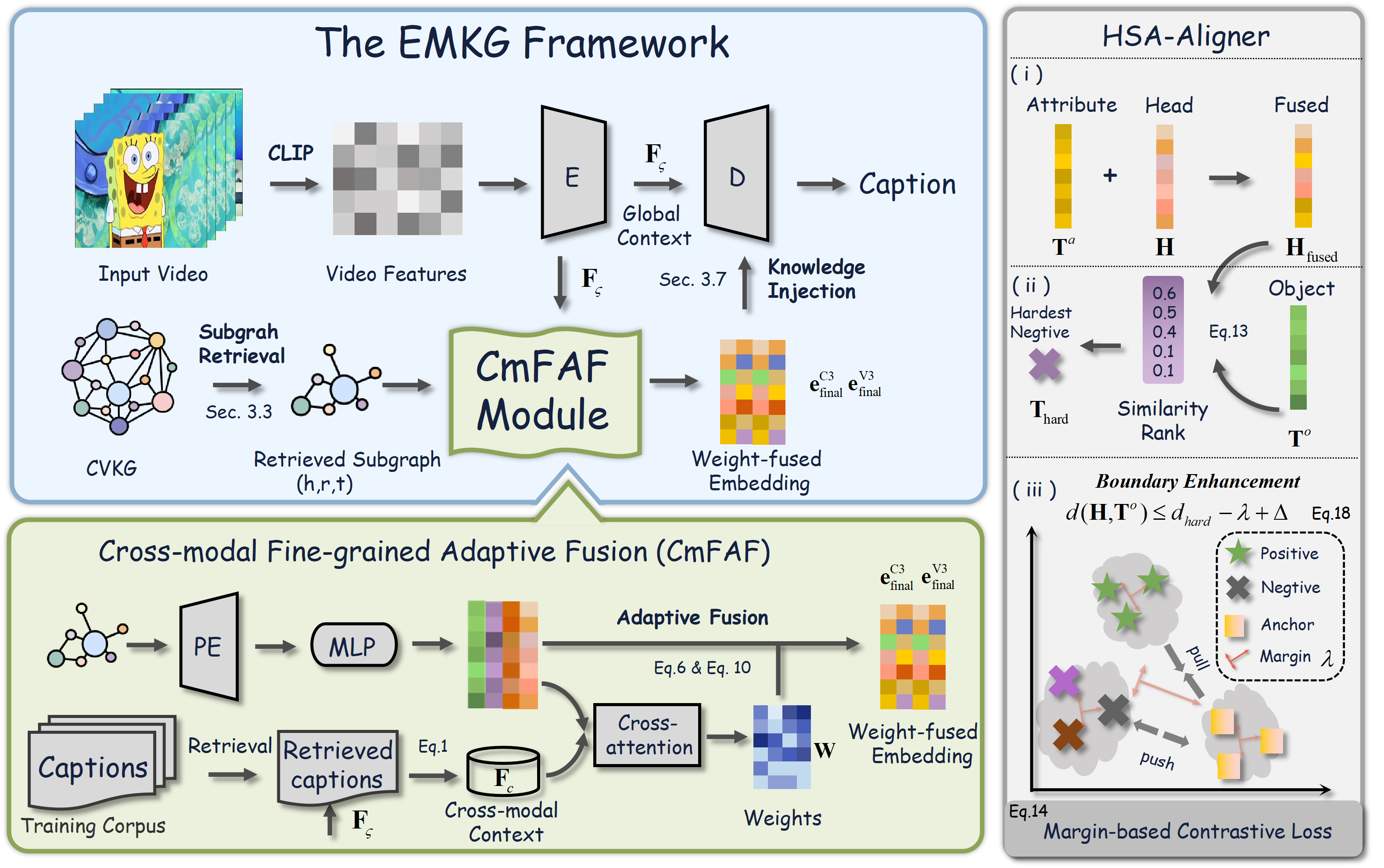
Towards Generalized Video Captioning: An Effective Multi-modal Knowledge Graph Perspective
Haoying Sun, Shuyi Li, Zeyu Xi, Lifang Wu, KNOWLEDGE-BASED SYSTEMS, 2025, IF=7.6, JCR Q1, SCI 1 top, project page / paper We propose an EMKG framework for video captioning, which enhances generalization via a ConceptVision Knowledge Graph (CVKG) with two subgraphs: ConceptCore (C3) and VisionVivid (V3). To reduce noise, Cross-modal Fine-grained Adaptive Fusion (CmFAF) dynamically adjusts node/relation weights using cross-modal context. Hardest Sample Attribute-anchored Alignment (HSA-Aligner) improves visual-textual alignment via attribute-guided hard negative mining. Experiments on MSR-VTT and MSVD show EMKG outperforms state-of-the-art methods with superior generalization. |
|
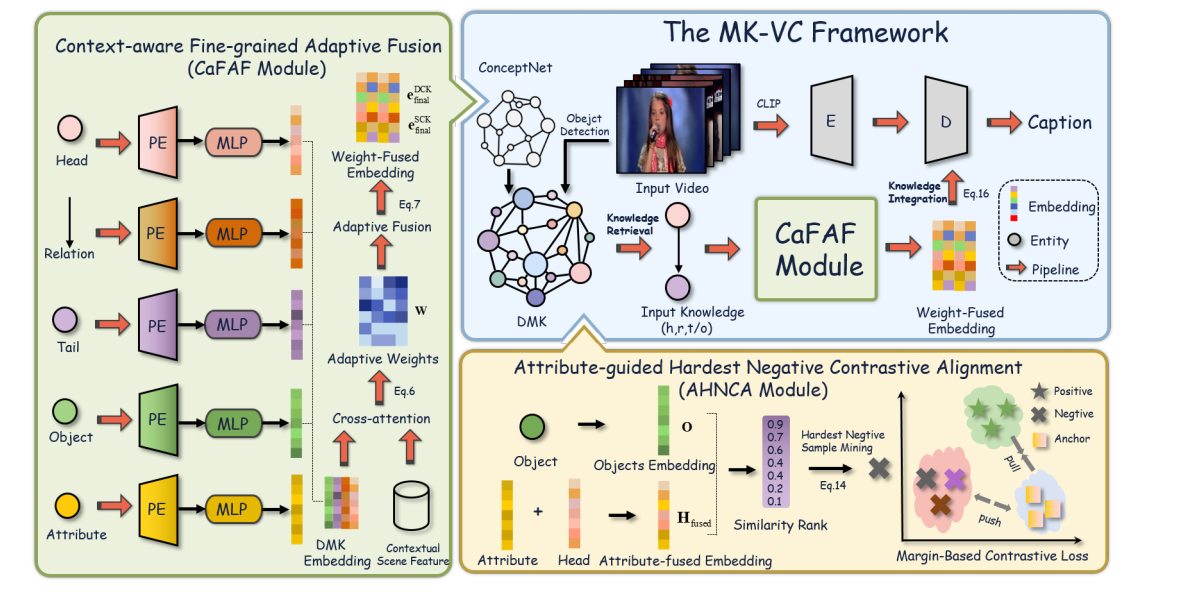
Scene Adaptive Dynamic Multi-Modal Knowledge for Video Captioning
Haoying Sun, Shuyi Li, Zeyu Xi, Yunhao Zhao, Haoran Zhang, Lifang Wu, Expert Systems with Applications, 2025, IF=7.5, JCR Q1, SCI 1 top, project page / paper This paper proposes a multi-modal knowledge framework (MK-VC) for video captioning that specifically targets the challenging long-tail word distribution problem. By integrating dynamic context and static concept knowledge through fine-grained adaptive fusion and attribute-guided alignment, the framework enhances caption generation and effectively handles rare and infrequent words. |
|
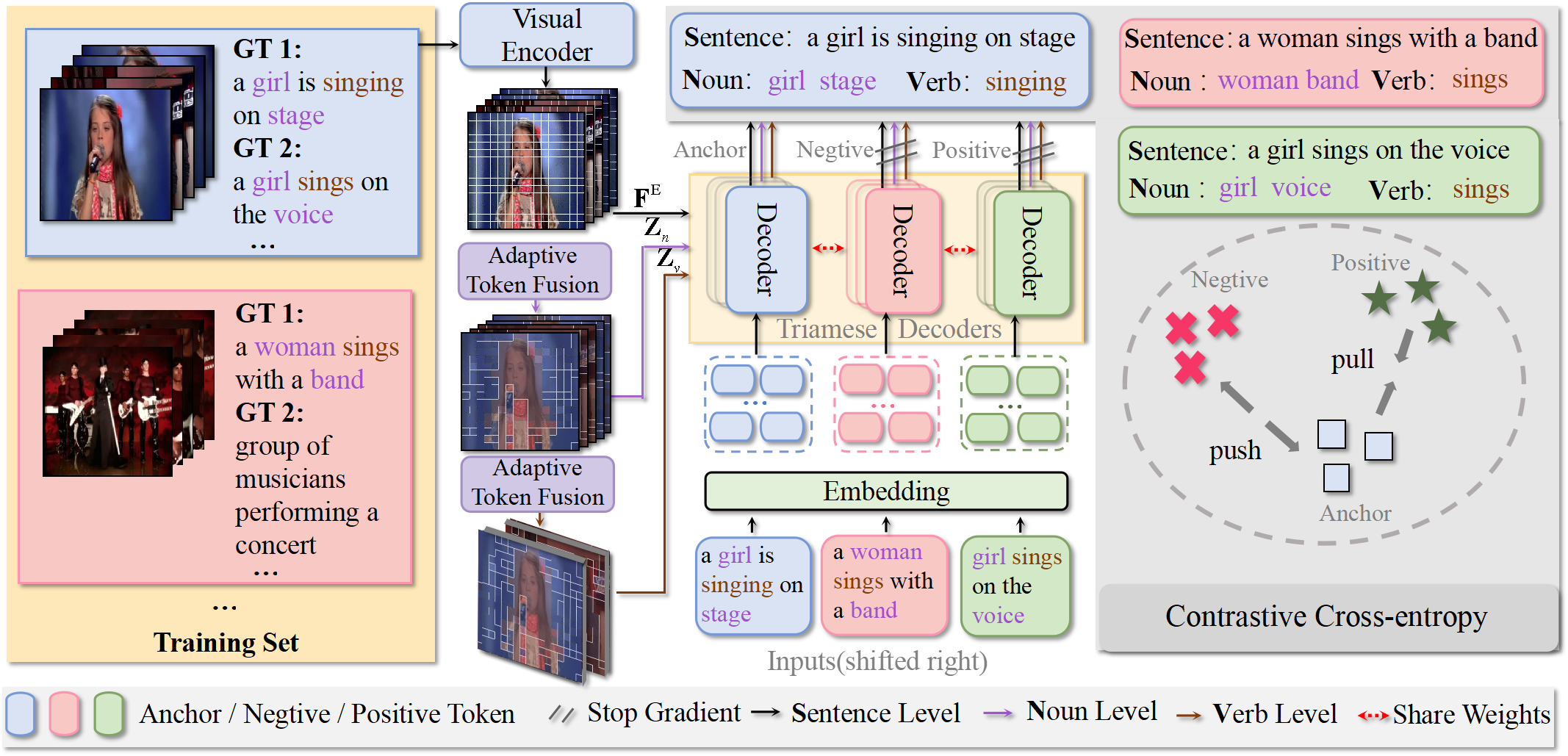
Unified Hierarchical Contrastive Learning for Video Captioning
Haoying Sun, Shuyi Li, Zeyu Xi, Lifang Wu, Information Fusion, 2025, IF=15.5, JCR Q1, SCI 1 top, project page / paper We proposed UHCL, a unified hierarchical contrastive learning method for video captioning that enhances caption distinctiveness and overall performance, using triamese decoders and adaptive token fusion, achieving state-of-the-art results on the MSR-VTT and MSVD datasets. |
|
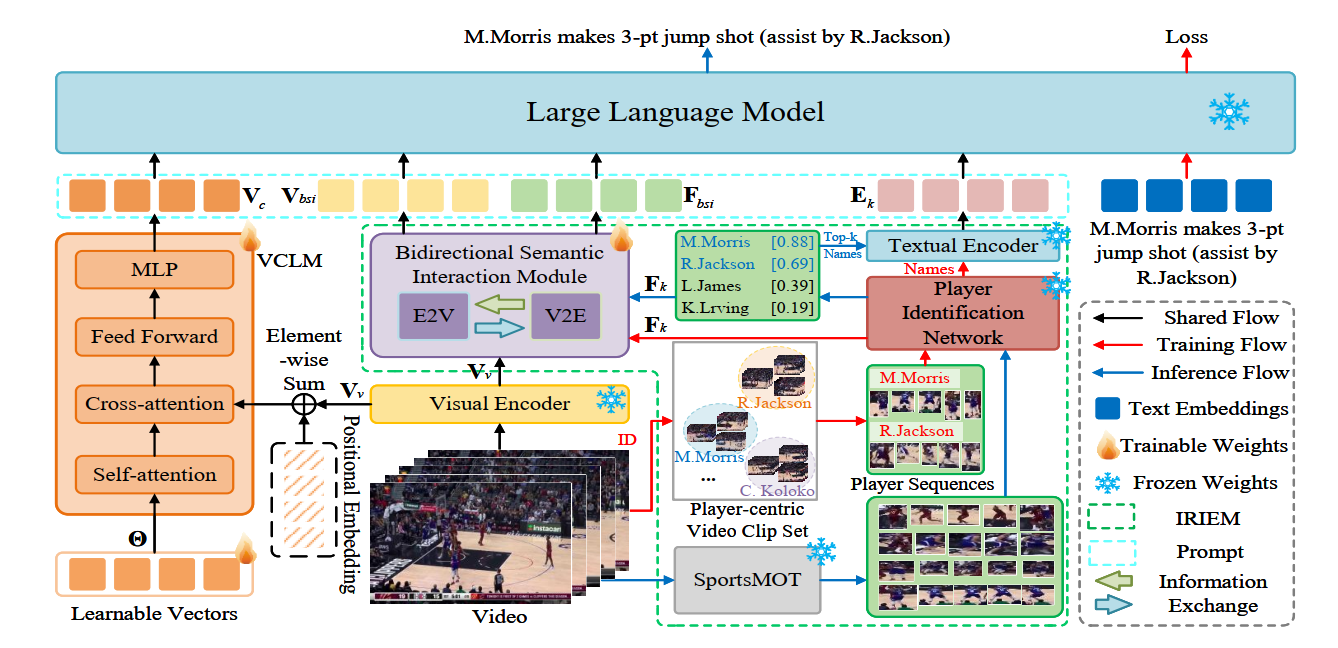
Player-Centric Multimodal Prompt Generation for Large Language Model Based Identity-Aware Basketball Video Captioning
Zeyu Xi, Haoying Sun, Yaofei Wu, Junchi Yan, Lifang Wu, Liang Wang, Changwen Chen, ICCV, 2025 (Poster) , CCF-A project page / arXiv We developed LLM-VC, a player-centric multimodal prompt generation network for identity-aware sports video captioning, which integrates visual and semantic cues to recognize player identities and generate accurate, player-specific descriptions, achieving state-of-the-art performance on the new NBA-Identity and VC-NBA-2022 datasets. |
|
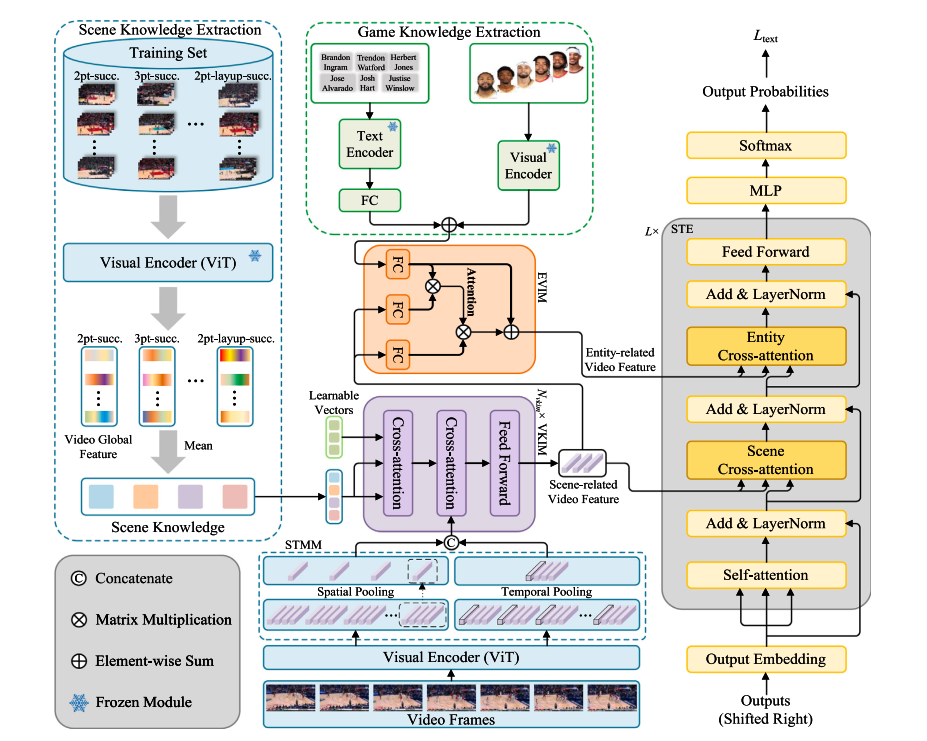
EIKA: Explicit & Implicit Knowledge-Augmented Network for entity-aware sports video captioning
Zeyu Xi, Ge Shi, Haoying Sun, Bowen Zhang, Shuyi Li, Lifang Wu, Expert Systems With Applications, 2025, IF=7.5, JCR Q1, SCI 1 top, project page / paper We proposed EIKA, an Entity-Aware Sports Video Captioning framework that integrates explicit player knowledge and implicit scene understanding to generate fine-grained, informative captions, achieving state-of-the-art results on multiple benchmark datasets. |
|
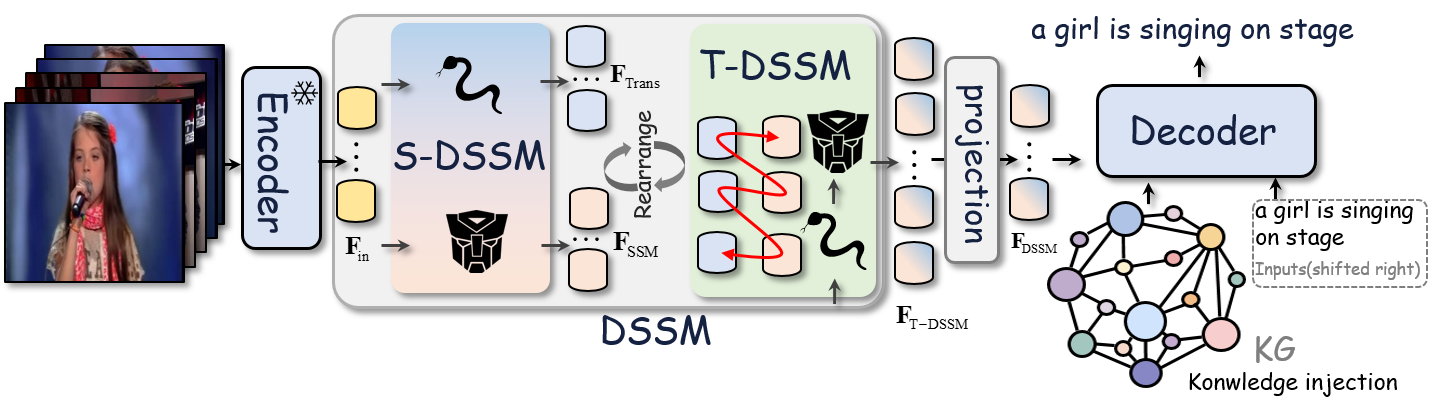
DSSM-KG: Dual-Stream State-Space Modeling with Adaptive Knowledge Injection for Video Captioning
Haoying Sun, Shuyi Li, Zeyu Xi, Bowen Zhang, Lifang Wu, ICMR, 2025 (Oral Presentation), CCF-B project page / paper We propose DSSM-KG, a dual-stream state-space model with cross-modal knowledge injection for video captioning. By integrating Transformer–Mamba hybrid modules for joint spatiotemporal modeling and adaptively injecting a commonsense-enhanced knowledge graph, DSSM-KG achieves competitive results on MSVD and MSRVTT. |
|
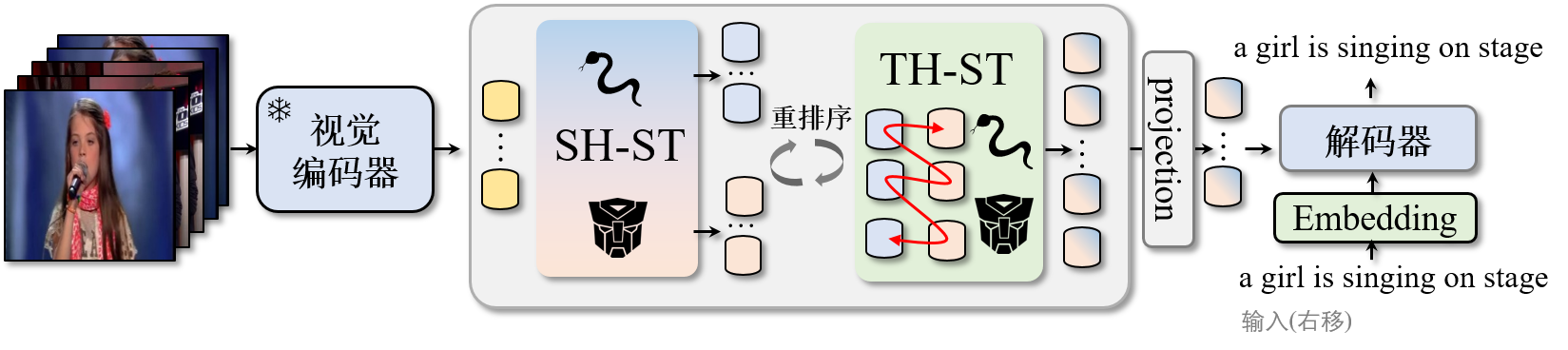
结合状态空间模型和Transformer的时空增强视频字幕生成 (Spatiotemporal Enhancement of Video Captioning Integrating a State Space Model and Transformer)
Haoying Sun, Shuyi Li, Zeyu Xi, Lifang Wu, 信号处理(JOURNAL OF SIGNAL PROCESSING), 2025,北核 project page / arXiv This paper proposes ST2, a SpatioTemporal-enhanced State Space Model and Transformer for video captioning, which integrates Mamba and Transformer in parallel to achieve efficient spatiotemporal joint modeling, achieving competitive performance on MSVD and MSR-VTT datasets. |
|
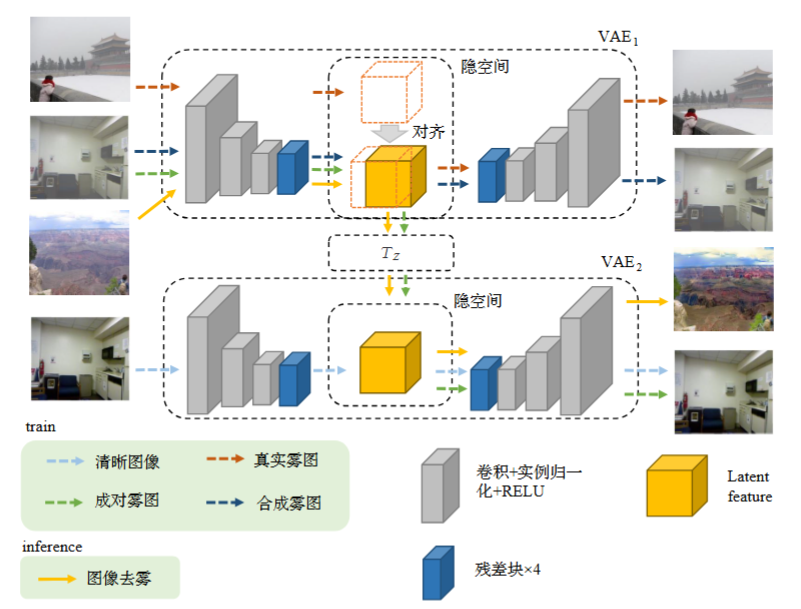
隐空间转换的混合样本图像去雾 (Hybrid Samples Image Dehazing via Latent Space Translation)
Yutong Zheng, Haoying Sun, Wei Song, 计算机工程与应用 (Computer Engineering and Applications), 2023 , 北核 project page / arXiv We proposed a VAE-GAN-based hybrid sample learning framework for image dehazing that jointly leverages synthetic and real data through latent space alignment and feature-adaptive fusion, achieving clearer dehazing results and higher PSNR on real-world hazy images. |
Miscellanea |
Micropapers |
None
None |
Recorded Talks |
None None |
Academic Service |
None
None |
Teaching |
None
None |
|
Feel free to steal this website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |